How do you debug a webpage that loads in 15sec?
A recent question a chap asked me some time ago was, How do you debug a webpage that loads in about 15sec? Though, open-ended there are a couple of things one can reason about to answer this question.
Identify the bottleneck?
We can start by using a logging and monitoring tool to figure this out, but let’s a take a step back to consider what could potentially be the cause of this issue from the frontend before considering the backend.
Performance: a slow system for a single user
Chrome DevTools can come in handy here to allow you to figure out what part of your application needs to be fine-tuned, from CSS rendering to Javascript parsing, to network speed, memory issues etc. Another critical concept to look out for here is the critical rendering path. Knowledge of these can help figure out if indeed the problem comes from the front end. As for the backend, we can consider using tools like Datadog, the Elastic stack, Prometheus, Graphana, Graylog and the likes to monitor request-response time, trace application functions time and collect Application performance metrics to figure out what part of the system we need to optimise. Let’s not forget about the DB queries; we can index DB columns that are frequently used to optimise queries which can also go a long way to help improve the system performance, last but not the least to consider is caching, by caching data we can use what’s stored in the cache to respond to request. Caching has some things to consider like client, CDN, web, database or application caching. I suppose this is not all we can do but this is a good starting point. Hopefully, we would have figured out the issue by now.
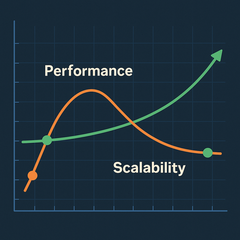
Scalability: a fast system for a single user but slow under heavy load
What if the load (an increase in the average request per sec) on the system is so much that the page takes about 15sec to load? In times like this, we can consider using our logging and monitoring tool to figure out what part of the system is over utilised and worthy enough for us to break out as a service or we could consider scaling vertically, i.e. Increasing metrics like CPU, ram, IOPS and storage. Another form of scaling would be horizontal, that is increasing the number of machines that run the same application and putting all these machines behind a load balancer that direct traffic to these machines using specific rules.
Are we done?
It depends; we briefly examined what could potentially be the cause of the problem defined above and how we can address it. You can take this further by trying to figure out the best set of possible solutions to this problem.
Originally posted on my medium page